
◎林澤民/美國德州大學奧斯汀分校政府系教授
編按:本文原發表於作者的個人部落格,並由PanSci泛科學以專欄文章的形式來轉載。林教授也補充了一則〈後記〉在FB,用更淺白的話語來解釋文中的一些概念。菜市場政治學邀請林教授來分享這兩篇文章,向讀者們解說最近很紅的對比式民調。
媒體一再以抽樣誤差為標準來判定對比式民調中候選人支持度差距是否具有統計顯著性,這是對選舉民調的錯誤解讀。這種錯誤,不但國內媒體常犯,國外亦然。而且不但媒體,連影響重大的政黨提名制度也犯同樣錯誤。
來源:中天新聞截圖
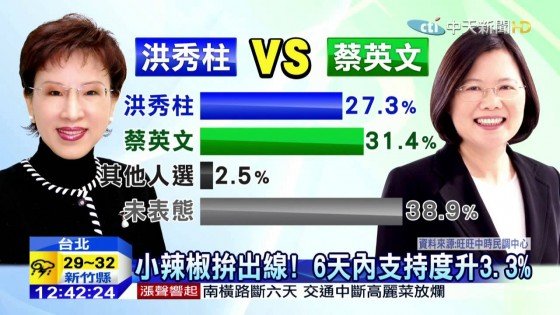
以六月四日發表的旺旺中時民調為例,王金平與蔡英文的對比式民調結果是蔡29.5%王26.6%,差距2.9%。該民調成功訪問773人份有效樣本。在95%信心水準下,抽樣誤差為正負3.5%。中時因此強調王蔡之差「在誤差範圍內」。同一民調也對洪秀柱與蔡英文作對比式民調,結果是蔡31.4%洪27.3%,差距4.1%。中時雖未說明此差距是否在誤差範圍內,對照上文,該報導顯然認為蔡、洪的差距大過抽樣誤差而具有統計顯著性。
類似的民調解讀,我在美國媒體上也常看到。隨手捻來:2012年三月美國總統大選政黨初選期間,CBS News/New York Times合作民調顯示民主黨的Obama領先共和黨的Romney 47%對44%。CBS的記者作文字報導時,一樣強調「三個百分點的領先是在該民調的3%抽樣誤差範圍之內」。
這樣的解讀為何錯誤?
一般民調的所謂抽樣誤差,其實是在該民調的樣本數下,50%這個百分比的抽樣誤差。即使可以用公式算出其他百分比的誤差,它也只適用於衡量單獨一個百分比。要衡量「兩個百分比差距」的誤差,必須要用不同的算法。舉例而言,假設民調中所有的受訪者均支持兩位候選人之一,也就是沒有人支持第三候選人也沒有人未表態。這種情況下,如果對比候選人A的支持度為p,則對比候選人B的支持度為1-p,其差距為p-(1-p)=2p-1。因為單一百分比p的誤差是抽樣誤差m,2p-1的誤差是2m。換句話說,判定候選人民調支持度差距是否具有統計顯著性的標準不是抽樣誤差而是抽樣誤差的兩倍!假如抽樣誤差為3.5%,A的支持度為53%,B的支持度為47%,則A-B的6個百分點的支持度差距在統計上並不顯著。這個結論其實並不令人詫異,因為就個別百分比而言,53%和47%其實在統計上和平分秋色的50%都沒有顯著差異,因此兩位候選人的支持度其實難分軒輊,必須要差距超過7個百分點才能真正分出勝負。
然則正確的選舉民調解讀一定要用兩倍抽樣誤差作為衡量標準嗎?
這也不然,原因是一般對比式選舉民調容許受訪者支持第三位候選人或者不表態,在對比的兩位候選人支持度總和小於100%的情況下,以上的分析並不成立。真的要用「兩倍抽樣誤差」作為標準,必須要先把候選人支持度「正規化」:丟棄不支持對比候選人或不表態的受訪者而把有效樣本局限在支持對比候選人的受訪者之中,然後以此縮小樣本為基底重新計算百分比。這樣做,有效樣本數通常會顯著減小,因而導致抽樣誤差(以及兩倍抽樣誤差)增大。以中時洪秀柱對蔡英文的對比式民調為例,兩人支持度總和只有58.7%,換算成有效樣本數773×58.7%≈454,抽樣誤差增為4.6%。在這有效樣本的基礎上,原來蔡對洪的31.4%對27.3%正規化為53.5%對46.5%,差距也變成7%。這差距雖然在縮小後樣本的抽樣誤差之外,卻在兩倍抽樣誤差之內,也就是洪與蔡的對比,其實在統計上也是難分軒輊!
然而更正確的做法,要用下圖中的公式來計算兩個百分比差距的抽樣誤差。注意:式中的p1和p2是原樣本中百分比所對應的實數(也就是百分點除以100所得的介於0和1之間的數)而不是百分點,N是原樣本數,1.96是基於95%信心水準算得的常數。
![]()
再以中時洪秀柱對蔡英文的對比式民調為例,如果蔡英文的支持度為p1,洪秀柱的支持度為p2,則p1=0.314,p2=0.273。套入公式計算得到差距p1-p2的誤差為0.054或5.4%;原樣本中的差距4.1%是在抽樣誤差之內,也就是洪蔡對比和王蔡對比一樣,都是難分軒輊!根據此一公式,兩個百分比差距的誤差一定大於單一百分比的抽樣誤差。
國民黨最近修改區域立委現任者徵召辦法。根據原來的辦法,現任區域立委有連任意願,但同一選區內有同黨挑戰者參選,則該立委在通過幹部評鑑後,必須進行與挑戰者的對比式民調。如果現任立委的民調支持度領先挑戰者3%以上,黨的輔選策略委員會得提報中常會直接徵召,免進入初選階段。但若現任立委未領先挑戰者或領先未逾3%,則必須進入協調或初選階段。新的辦法把3%門檻改為5%。根據國民黨文傳會主委林奕華解釋,「有關現任立委民調支持度門檻,考量3%差距通常屬民調誤差範圍,歸納以往選舉民調經驗,最後決定以5%做為門檻。」(以上根據自由時報2015-03-18報導)
國民黨顯然與媒體同樣犯了選舉民調解讀的錯誤,以一般民調的3%抽樣誤差為標準來判定候選人支持度差距是否「顯著」。現在改成5%雖然有進步,但正確的民調差距誤差,會隨著p1、p2、和N而有所不同,5%仍然是一個沒有科學根據的數目。至於民進黨,其公職人員初選辦法則完全不考慮抽樣誤差。
台灣的總統大選在選舉日前有10天的民調封關期,在此期間,任何個人和機構不得發表民調結果。世界上最少有90個以上的國家有最少選前1日以上的民調封關規定。這種民調封關期的制度很顯然是基於民調可以左右選民抉擇的假設,以封關來避免不論是正確或錯誤的民調來影響選民的個人選擇。然而既然相信民調可以影響選舉結果,我們對於如何正確解讀選舉民調豈可不審慎呢?
來源:TVBS新聞截圖
〈對比式民調的錯誤解讀〉後記
〈對比式民調的錯誤解讀〉一文刊出後,有讀者希望能夠有懶人包或簡化版。這裡稍微用比較平易的話把一些統計觀念和文章大意再說明一下。
抽樣誤差
民調因為使用樣本(通常約N≈1,000左右的受訪者)的統計數字來估計母體(所有選民)的真正值,會有誤差。例如某機構民調測得某候選人的支持度是48%,這是受訪者的48%,並不是所有選民的48%。統計推論讓我們能夠用樣本的估計值來推論母體的真正值,其方式是在一些假設之下算出所謂的抽樣誤差。一般嚴謹的民調都會明白報告其抽樣誤差,例如:「本民調共成功訪問N人份有效樣本。在95%信心水準下,抽樣誤差為正負mx100%。」假如上述某機構的有效樣本數N=1,070,則其抽樣誤差m=±0.03或±3%。樣本數越大,抽樣誤差越小。
信心區間
「在95%信心水準下,抽樣誤差為±3%」是什麼意思?繼續以樣本測得的48%支持度而言,它意指我們有95%的信心母體的真正值是48%±3%,也就是在45%和51%之間。這(45%, 51%)就是所謂的95%「信心區間」,其意函是母體真正值不在這區間的機會只有5%。
抽樣誤差不是對比差距的誤差
但民調報告的抽樣誤差有其局限性:第一,它只適用於樣本支持度在50%左右;支持度若偏離50%,抽樣誤差會較小。第二,它只適用於衡量支持度或單一百分比的誤差;在對比式民調中,我們關切的是兩候選人支持度的差距,民調報告的抽樣誤差不能直接拿來推論母體中兩候選人支持度的差距。國內外媒體在這兩點上一再地犯錯。
例如六月四日旺旺中時民調的有效樣本數為N=773,算得抽樣誤差3.5%。該民調測得蔡英文29.5%王金平26.6%,差距2.9%。用3.5%的抽樣誤差來算95%信心區間得(-0.6%, 6.4%),因為這區間包含0,所以2.9%的差距在統計上和0是沒有顯著差異的,這也是中國時報說蔡王之差「在誤差範圍內」的緣故。這樣的推論方式其實是錯誤的,因為3.5%雖然是民調報告的抽樣誤差,卻不是對比差距的抽樣誤差。同理,該民調測得蔡英文31.4%洪秀柱27.3%,差距4.1%。雖然用3.5%的抽樣誤差來算95%信心區間(0.6%, 7.6%)在0之上,但這也不能推論說蔡、洪的差距在統計上是顯著的。
為什麼不對?這道理很簡單:以蔡、洪對比為例而言,支持度30%左右的抽樣誤差其實要比3.5%小,只有3.2%,但重點是不但蔡英文的31.4%有誤差,洪秀柱的27.3%也有誤差,兩個各有誤差的數字相減,其差距的誤差會比單一支持度的誤差要大,最大可以大到兩倍。因此,媒體慣常用差距是否在抽樣誤差之內來判定差距顯著性的作法是錯誤的。
〈對比式民調的錯誤解讀〉提出一個可以正確計算對比差距抽樣誤差的公式,用這公式來算,蔡英文31.4%對比洪秀柱27.3%的差距在統計上是不顯著的,也就是用媒體慣常推論法會得到錯誤的結論。
來源:風傳媒報導新台灣國策智庫6/12公佈的民調