
◎陳方隅/美國密西根州大政治所博士候選人
「80%韓國人說喜歡吃泡菜,75%日本人說喜歡吃壽司,所以泡菜贏過壽司?」
—網路鄉民
《天下》和《遠見雜誌》每年固定發佈的縣市長滿意度調查,總會引起新聞媒體的大幅報導。2016年的縣市長滿意度調查剛剛發佈不久(調查請點此:連結),大家不免又是將焦點集中在某幾位政治明星身上。其實,若了解一些統計或調查研究的原理,應該要能判斷,這份「排名」就是僅供參考而已,並不能反映真實狀況。就讓我們順道來理解一些民調抽樣的名詞吧!
民調的背景脈絡問題
首先,這樣的民調總是無法避免「張飛打岳飛」的謬誤,因為「主觀」的民調數據是不能拿來做排名比較的。在各縣市「分別」抽樣調查,每個地方應視為獨立的一次調查。「滿意」是一個主觀的形容詞,其定義對每個人來說都不一樣,在各縣市也可能會有所不同,受訪者所回答也會受到很多因素的影響,例如調查時間、最近該縣市有無重大事件與爭議、訪員素質等等,如果要拿來排名比較的話,必須假設所有人都是以同樣的方式理解同樣的問卷問題(例如,在2015年的調查,大家對新北市長朱立倫的施政評價,很有可能摻雜了他當國民黨黨主席的評價,甚至是國民黨整體表現的評價)。我看到一位學長的舉例很有意思,他說:80%韓國人說喜歡吃泡菜,75%日本人說喜歡吃壽司,所以泡菜贏過壽司?
 泡菜拉麵示意圖。來源:山本堂日式拉麵提供
泡菜拉麵示意圖。來源:山本堂日式拉麵提供
讓問題更複雜的是,《天下》的調查是用加權算出的分數,問了民眾總體施政滿意度(30%)和「五力」的滿意度(各10%),再請一組專家來評論總體滿意度(10%)和分項滿意度(10%)。這五力是指經濟力、環境力、施政力、文教力、社福力,然而,各縣市的民眾對這五力的理解真的是一樣的嗎?在專家學者部份的加總也是有點問題,因為他們是請來各縣市不同的專家學者做評比。這樣的多指標民調好處是可以補足以往民調「單一問題」的不足,但是要直接加總主觀的意見並且做排名是不適當的。只有客觀的數據可以直接拿來排名,主觀的數據不行。
民調的抽樣問題
第二,也是最大的問題之一,就是這個排名沒有考慮到抽樣誤差。
面對樣本數的不同,根據《天下雜誌》的說明,「當信心水準在95%時,每個縣市的抽樣誤差為正負3.1至4.2個百分點」。這句話是什麼意思呢?讓我們來談談一點統計原理吧!
其實,我們並不知道真實狀況到底一個縣市長的滿意度到底是幾趴,因為我們不可能調查「每一位居民」,所以只能「抽樣」。只要有抽樣,一定有誤差,而且,這個誤差值的大小是依據樣本的數目所決定。1
讓我們假設一下「真實狀況」:一個縣市有100萬人,然後有60萬人對縣市長滿意,40萬人不滿意,真實滿意度是60%(這個真實的數據,我們稱做「母體平均數」)。假設今天我們從100萬人當中抽1000位左右出來,我們不可能剛剛好抽到600個人是覺得滿意而400個是覺得不滿意,有可能某次調查「剛好」都抽到一些某類相同意見的人,有時候會抽到那40萬說不滿意的人多一點,有時候抽到那60萬說滿意的人多一點。統計學家告訴我們,如果我們抽樣「無限多次」,把每次抽樣得到的平均滿意度都記下來,這無限多次抽樣得到的滿意度會呈現常態分布(可想像成:把這無限多次的滿意度平均起來會接近真實的60%)。不過,最大的問題就是——我們每個民調都只能抽一次!
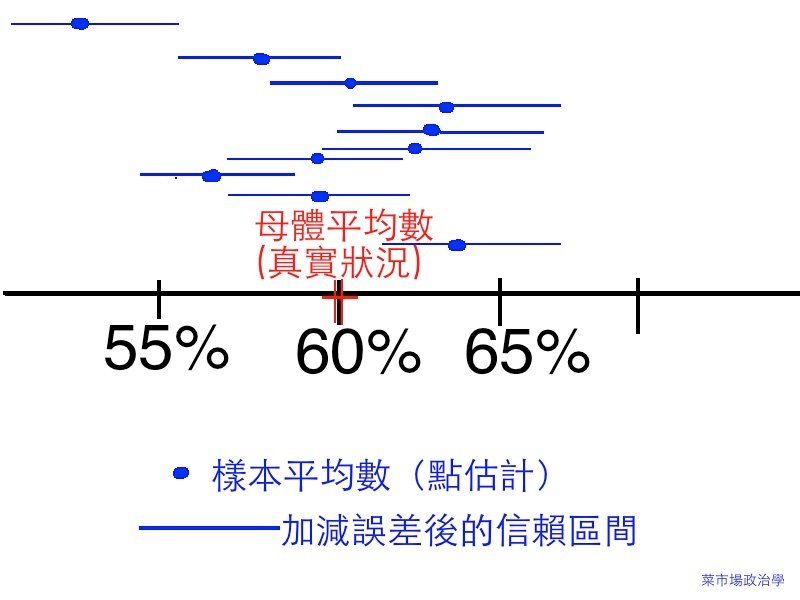
說明:每條線都是一次抽樣的結果。每抽一次會得到一個平均數(樣本平均數),再加減誤差後,形成信賴區間。
因此,雖然字面上是「誤差」,但這不是一件壞事。抽樣調查的結果,我們會「加減」誤差,說是一個區間值。「當信心水準在95%時,某縣市的抽樣誤差為正負x個百分點」意思是說,每抽樣100次會有100個區間,而統計學家宣稱這100個區間,有95次的結果會包含「真實的那個母體平均數百分比」。2
所以問題來了,看看這份縣市長排名,抽樣誤差隨著樣本數的不同,在每個縣是3.1%至4.2%,其實很多縣市長的滿意度之間根本沒有「統計上的顯著差異」。讓我們先不考慮《天下》這份調查當中,各項施政分數的加總問題及專家評比部份,先把這些項目整體視為一個滿意度的值。假設以750份樣本來說,誤差是3.5%左右,像是第三名的高雄市長陳菊,其施政民調是落在69.6%加減3.5%之間,最低有可能是66.1%;第9名的澎湖縣長陳光復,分數可能落在63.08%加減3.5%,最高有可能是66.58%。換句話說,第三名和第九名的縣市長,在總體施政分數當中,由民調決定的那80%部份,可能是沒有顯著差異的。3
比較好的方式,應該是做一個等第。例如有幾位首長落在第一等第(或是五星之類),幾位落在第二區(四星),幾位是在墊底區。但是這種方式有個爭議就是如何訂出幾星或幾區的標準。這時候,下一個標題「五星縣市長」之類,還是一樣可以製造聳動效果。
可以確定的是,用主觀的調查資料來做個別的排名不僅是做不到,而且也沒有意義的。以往的調查當中,每次媒體都會去排出一位首長跟去年相比進步或減少幾名這樣的資訊,這次也不例外。不過,有時候可能單純就是因為抽樣誤差而造成的排名改變而已。例如,在2015年調查當中,《天下雜誌》在第一段就特別點出台南市長賴清德總體施政滿意度減少2.4%,並說「『賴神』的高人氣已出現反轉訊號」。但是這仍然在抽樣誤差之內,也就是說今年的88.1%和去年的90.5%是沒有統計上的顯著差異的。這次2016調查的第一段就寫說「國民黨執政縣市首度出現一致性微幅進步」,但所謂「進步」的分數大都在抽樣的誤差範圍內(劉增應名次從第二升為第一,分數+2.07;黃健庭名次+2為8,但分數退步3.66;林明溱名次+1為15,分數+3.9;朱立倫名次+1名但仍為倒數的第19名,分數+0.17),這種分數或名次上「微幅」的進步有可能都是由抽樣誤差造成的(更何況還有人實質分數退步),不是「真正」的進步。不過,媒體有銷售市場考量,可能一定要做「排名」才夠有新聞話題性吧?
民調的執行問題和詮釋問題
第三,電話調查有一些侷限性。例如現在很多人持有手機及行動上網的裝置,但沒有室內電話,尤其年輕族群、在外工作或讀書的族群;例如若是白天做調查,則上班族永遠不會被調查到。所以這個樣本的「代表性」很可能會有一些問題,也就是說可能會偏向某一類工作型態的人的意見。另外,在執行問題方面,問卷內容的問法、選項內容和排序等都會直接影響回答結果(例如某民調機構曾做出台灣有七成五的民眾自認是中國人,但是一看問卷選項幾乎全部都有「中國人」這個詞),這點在縣市首長調查當中的問題比較不大,就先略過不談了。
第四,永遠要對媒體保持一定的質疑,千萬不要照單全收。媒體可能會下標引導讀者,或是加入一些主觀的見解。例如在2015年的報導中強調「柯P神話不如預期」因為他「只」排在第九名,然而,一看內容發現其實柯文哲上任以來,總體滿意度比前任郝市長高了19%。又如報導中說連任的首長「表現不突出」,但看一下發現其中被說是「退步」的像是東部三位首長黃健庭、傅崑箕、林聰賢,其實不過就是整體滿意度從「超過八成」下降到「接近八成」,這種程度的滿意度叫做退步有點說不過去吧?
第五,近幾年某位「五星縣長」被爆料出來,在提供非常大量的廣告及專案的標案給某媒體之後,該媒體就很恰好地出現了五星報導,大家才知道說原來這個五星標題,「有可能」是買來的。當然,我認為還是要去看媒體對於調查研究方法的說明是否完整,對於網路訊息也不可以全部相信。只是,現在民調數據充斥著媒體報導,我們隨時要保持開放的態度去檢證很多的事情,尤其在這種「業配新聞」滿天飛的時代。

圖片來源:C.C by Jonathan Feng
小結
綜上所述,這種排名就是給人們一個參考。我不是說我們完全不需要民調和評比,這篇文章的重點是,在不同縣市分別做調查之後,拿來直接做排名,在學理上是說不通的。因此,我們不需要去造神,也不需要去追問某幾位上升下降的縣市長說有什麼感想,反正他們的答案一定是謝謝指教,團隊會再加油。統計是很有趣的東西,但也很容易拿來混淆視聽。知道一點基本的統計常識是很重要的。
更重要的是,民調高低跟真實施政的狀況,往往也是有差異,民調高更不代表就不用再監督這位首長了(例:劉政鴻長時間在這種評比當中都名列前茅,但是他上任八年讓苗栗縣負債暴增三倍為648億元,更不用提他徵收了多少地;近期來說,最近屢屢造成爭議的高雄各地徵收事件,也沒辦法立刻反應在調查當中)。因此,除了主觀的意見很重要,在客觀的數據(例如縣市財政狀況),還有許多爭議事件的處理、人權保障方面,我們都應該持續監督政治人物才對。
※ 本文曾於2015年9月2日發表於UDN鳴人堂:80%韓國人喜歡泡菜,75%日本人喜歡壽司,所以泡菜贏過壽司?——談媒體報導縣市長排名的現象。
作者於2016年9月13日將文稿更新。
※菜市場政治學延伸閱讀:
〈關於「推論統計」與「無罪推論」:法院判決的類比〉
〈對比式選舉民調的錯誤解讀〉
〈政黨票民調如何對小黨不利?〉
〈與其信專家,不如信大家:什麼是「預測市場」?什麼是「未來事件交易所」?〉
〈什麼是「誘導式民調」?以MG149帳戶民調為例〉
- 在統計上,抽樣誤差其實只有跟樣本數有關係,而跟整體的母體數目沒有關係。因此,從全台灣2300萬人當中抽1000人來問說明天總統大選你會投誰,跟從新竹市40萬人當中抽1000人來問說明天大選你會投誰,誤差是一樣的。樣本數愈大,誤差愈小,但這個誤差也只是說我們所預估的信賴區間愈小。例如剛才的例子,我們在高雄市抽1000人,得知陳菊的滿意度是69%加減3%,如果抽2000人可能變成69%加減2.5%,一樣是一個區間的概念,我們一樣無法得知真實的滿意度,因為永遠沒辦法讓「每一個」市民都表態。
樣本數的決定,需要考量的是成本,因為樣本數愈大,調查的成本愈高。而且當樣本數愈來愈大的時候,能夠減少誤差的程度愈來愈低。一般來說,調查研究通常會使用1000人左右的樣本。
同樣的道理,很多時候台灣的政黨初選會採取「全民調」,這也是匪夷所思、獨步全球。我們常常看到其實兩個人的差距在誤差範圍內,統計上沒有差異,例如令人印象深刻的一個例子:2011年國民黨立委黨內初選,蔣孝嚴獲得35.398%、羅淑蕾35.976%(而且這民調還是用兩家民調公司的數字拿來加乘平均)。「黨內遊戲規則就是這樣,贏0.1也是贏,贏1票也是贏」(新頭殼newtalk 2011.04.24)。統計上完全大錯特錯,不過,政治問題跟統計問題當然是不一樣的,現實上政治問題永遠都是一種藝術。 ↩ - 我們稱為「信賴區間」,即民調做出來的那個百分比(統計上稱為點估計)再加減誤差。95%的信心水準是可以調整的,如果要讓這個數值更高,在樣本數不變的狀況下,必須加大誤差範圍讓信賴區間變大。一般來說民調數字都是使用95%。 ↩
- 需特別註明的是,在統計上要計算「兩個比例」的差距時,其「標準誤」與點估計的信賴區間計算方式不太一樣。也就是說,如果要算兩個比例是否有顯著差距的話,不是直接使用點估計時的誤差值和信賴區間,所以此處是假定3.5%左右,並非精確值。此處因篇幅關係先省去不談。 ↩