
◎ 王宏恩/美國杜克大學政治所博士候選人
隨著2016總統大選接近,2012大選的相關新聞又浮上檯面。當你google相關關鍵字時,進入眼簾的卻是一個動魄驚心的網站:2012台灣總統選舉作票事件簿!對於民主選舉來說,做票意謂著投票這個民主機制失靈,近而使得選出來的勝選者沒有民主正當性。那麼,2012到底有沒有做票?本文將先回應該網站上的判別方法,再提出兩個政治科學界常用檢定做票的統計方法,叫作選舉犯罪學(Election Forensics)。
從開票圖看作票?
在作票事件簿的網站中,一個重大的立論基礎在於馬英九的得票一開始落後蔡英文,開到一半後卻出現黃金交叉了!這個轉變加上其它一些事件,被連結成做票的證據。假如開票如抽樣一樣,應該要開票越多越逐漸接近真值,而不會出現黃金交叉……是嗎?
上一段描述的狀況,需要建立在兩個假設上:第一,各投票所的票差不多(所以國民黨開的較慢是故意的)。第二,各投票所馬蔡得票率差不多(所以一開始贏了穩定後就會一路贏到底,好像統計抽越多人越接近真值一樣)。
然而,假如考量進『各投票所投票張數不同』這個假設,而且假如『兩大黨在不同票數的投票所支持度不同』的話,那上述邏輯就不成立,也就是不可能光看開票回報圖就說中選會作票。最重要的是,本文要透過選舉結果來說明,『就算沒做票,也可能開票到一半出現黃金交叉』。
假如打開中選會的2012選舉資料,把各投票所的票統計一下,可以發現一個投票所的票最少是東吉村的31張、最多是十興里的2336張,各投票所的票數原本就落差很大,因此不可能假設各票點都會同時開完票。
那麼,投票數比較高的投票所,有比較支持國民黨嗎?似乎是有的。
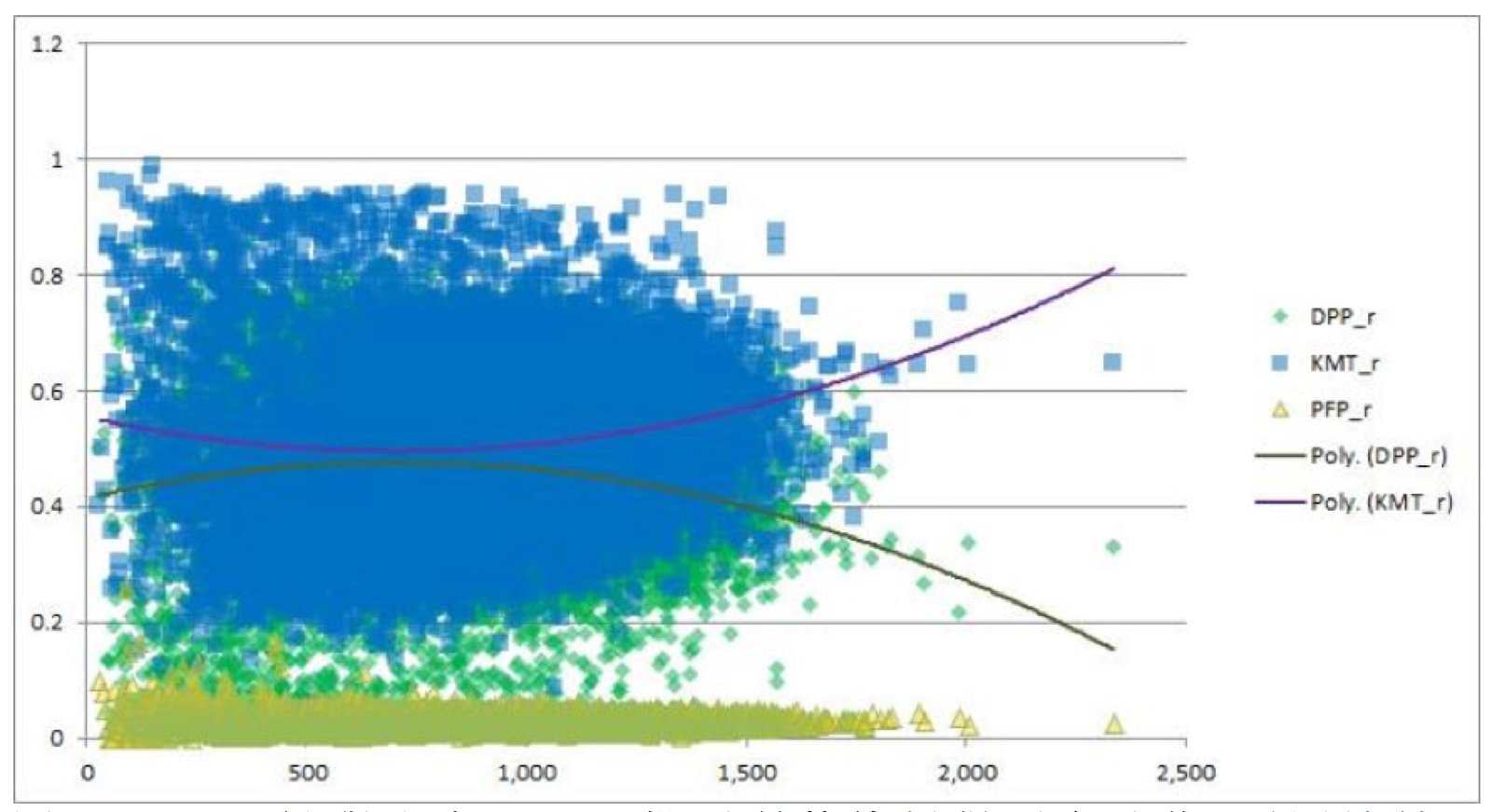
圖一的X軸是全台灣14806個投票所的投票張數,Y軸是三位總統候選人在各投票所的得票率,而藍綠兩條拋物線則是用excel跑的得票率趨勢線。從線上可以看出,國民黨平均而言在小票亭(離島、山區)跟大票亭(都市)得票較多,而民進黨平均在中票亭得票較多。尤其是票數1500以上的大型票匭,馬英九都拿超過6成以上的票。因此,除非國民黨在這些大型票匭都一起進行做票的動作,不然這些票匭本來就會比較晚開完,而讓馬英九後來超前。(p.s.前十大投票點分別是十興里 中寧里 萬和里 崇實里 武崙里 南勢里 新莊里 劉厝里 湖南里 華江里,他們有無可能做票呢?)
那麼,我們假設全台灣開票所人員的素質平均是一樣的,而票越少的票匭開越快並回報中選會的話,會得到什麼結果呢?

圖二的X軸是累積總有效票數、Y軸是三候選人累積得票率,而排列方式是依各投票點投票數來排(因為有廢票等也要認定)。假如票都是真的、各地依開票速度回報的話,一開始山地離島票開完自然國民黨大勝,但開到中選區時民進黨逆轉,因此在100萬至400萬票時都是民進黨獲勝中,可是等到大票箱也開完後,國民黨就會逆轉回來了。因為不假設各票點兩黨支持度平均相等、而是有歷史經濟社會背景因素導致落差,因此開票的過程並不像統計一樣抽樣越多越穩定,而是會有系統性的改變,故光看開票圖是看不出有作票的。真的有作票的話,應該也是做在其它地方,而不是中選會…….
最後,考慮到票數回報給中選會時可能是以369鄉鎮為單位,因此我也畫出了以369鄉鎮為單位的兩張分析圖。同樣地,國民黨在最大及最小的鄉鎮得票率較高,而民進黨在中間大小的鄉鎮得票率較高。
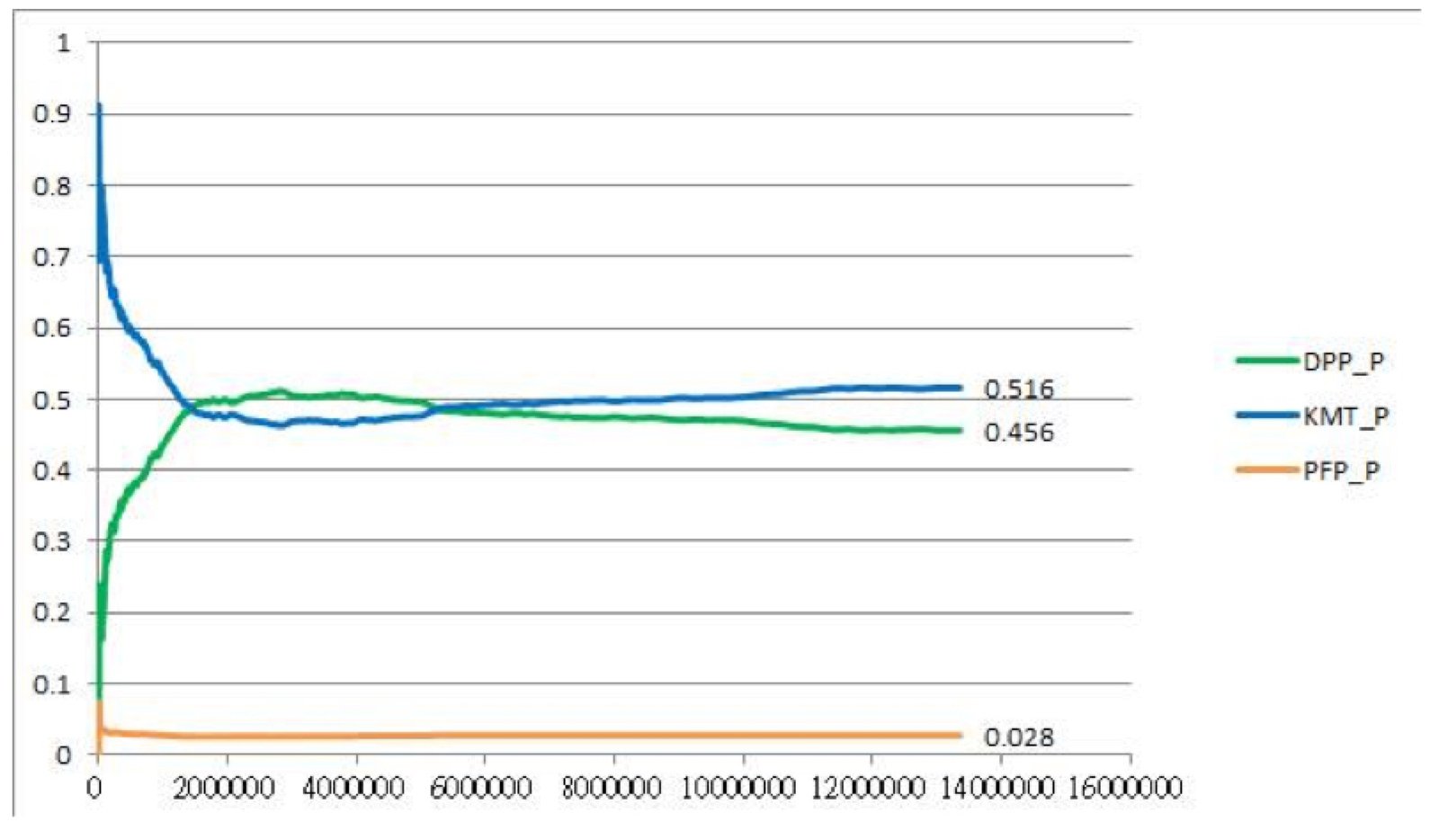
假如以鄉鎮為單位回報中選會,更能看出泛綠選民會失落的原因:一開始100萬至500萬票時明明都領先,但隨著較大的鄉鎮回報比較慢,因此開完一半票數時就忽然逆轉惹QQ (這張圖有沒有像做票事件簿裡抗議裡的兩候選人波動黃金交叉?)
因此,就算各個票點沒有做票,而是單純依照票數張數而在回報中選會上有順序差異,同樣會跑出黃金交叉的結果,故光憑這個交叉是不能證明有大規模做票存在的。
政治科學裡的選舉犯罪學
那麼,在政治科學中有測定作票的方法嗎?嚴格來說,沒有。假如我們知道的話這世界上就不會有作票了啊!(當然,可能也有那種大家都知道有作票但沒在管的,這是集體道德問題)。但假如寬鬆點來說,是有兩個快速的檢測方式:第一,Hotspot。第二,Benford’s Law。
這兩個方式的原先目的都只是在觀察資料點的分佈情形,並檢測資料分佈是否有異常之處。換言之,這就是選舉資料的快篩–快篩沒病不代表沒事,但快篩有病很可能有事,只是需要進一步調查。那麼,就來測試一下2012的總統選舉結果吧。
1. Heatmap
Heatmap的邏輯很簡單,就是把全部的投票箱作成散佈圖,其中X是投票率,Y是執政黨得票率。換言之,假如有一大群投票箱投票率極高、同時執政黨得票率也極高,那就可能有問題,例如這篇paper講解偵測俄羅斯跟烏克蘭的問題,忽然有一堆村里投票率超高又全都支持執政黨,讓整個票數分佈有兩三個高峰,那顯然就是有問題了吧!
那麼,台灣呢?下圖為2012年全台14807個投票箱的投票率與馬英九的得票率heatmap圖。(我用R裡的ggplot2中的geom_hex()畫)

從圖四來看,你很難說國民黨得票有不正常之處,分佈圖非常集中,可能作票的圖右上角並沒有特別的一塊出現。此次2012選戰之激烈,都沒有出現這種情形的話,要嘛就是作票數不明顯,要嘛就是全台所有票匭都做了一點(但這顯然不太可能,因為地方選委會是地方縣市長指派的)。
另外一種可能的圖,是假設2008年不用作票(因為大家都知道會大勝) 2012需要作票 ,因此X軸是2012年比2008年新增的投票張數、Y軸是KMT馬英九2012年比2008年在所有票匭的新得票數。假如4年過後忽然票匭裡票變多、而且全是馬英九的,那就有可能是作票,對吧?我合併了2012與2008總統選舉資料,其中2008有14402個票匭,因為有選區重畫因素,所以我是先把票匭合併成村里為單位計算。
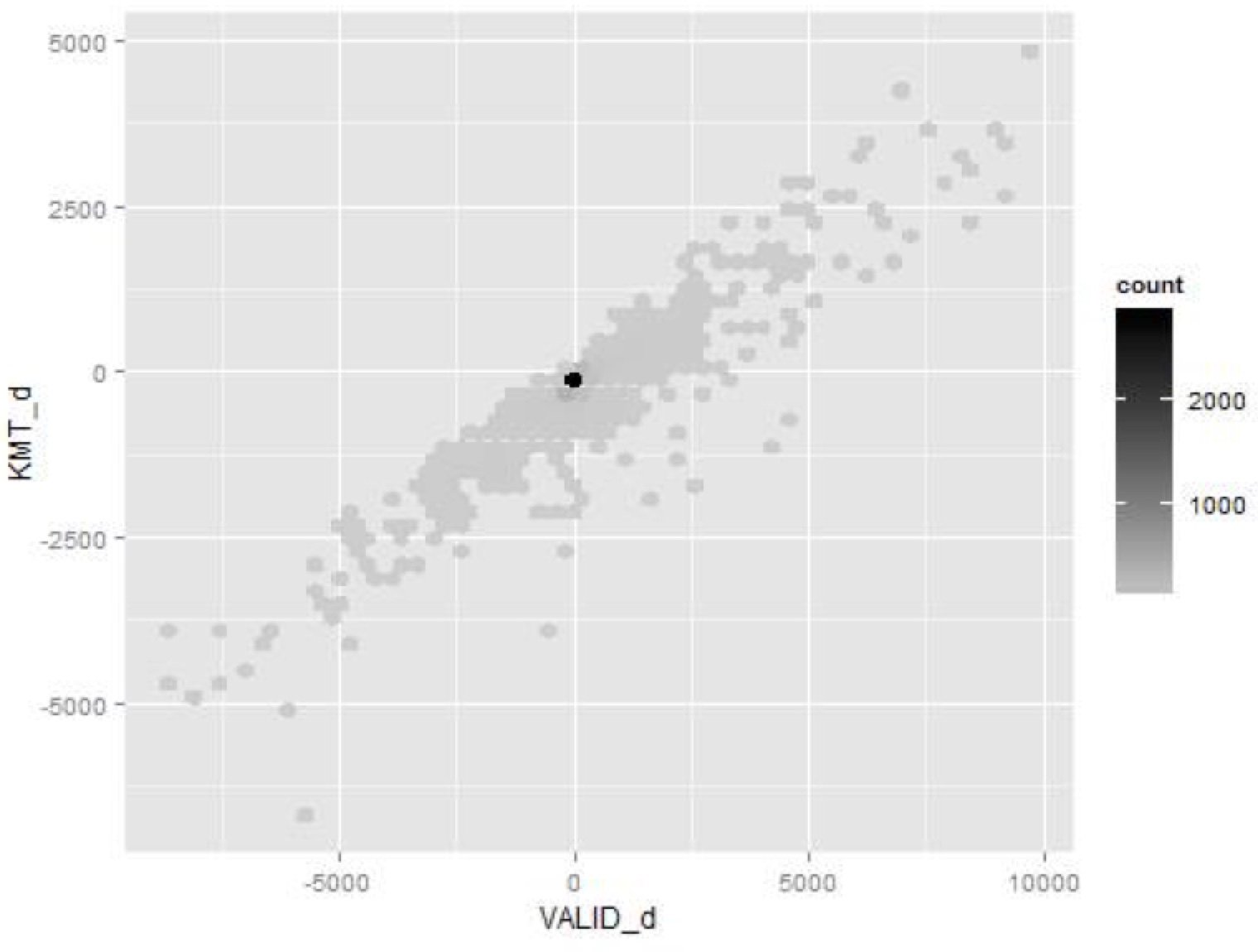
在圖五中,X軸的VALID_d是2012比2008在各村里多或少的票張數、而Y軸KMT_d是KMT馬英九2012比2008多或少的票數。從圖上來看,你很難說票數增減有特別對國民黨有利或不利—平均每多2人投票、國民黨就多1張票 ,反之亦然,這跟大選結果穩合,而可能作票的正上方也沒有特別的群聚。
筆者亦嘗試了各投票所投票率與馬總統新增票數,但同樣沒有看出明顯的問題。因此,光從肉眼看資料分佈,是看不出2012年執政黨有大規模系統性作票的情形,無法像之前提到的俄羅斯大選一樣看出不正常之處。
2. Benford’s Law
1881年的天文學家Newcomb與1938年的物理學家Benford分別提出,在自然界的數質資料的最高位位數分佈並非均等分佈,而是1最多(30%)、2其次…一路往下(x/x+1),因為自然界的數字是累積而上的。Benford拿了全美的各統計數字,包括河流長度、分子量、美國人口等都符合此一規律。 詳情可見此。
什麼情況會使資料不符合Benford’s Law呢?當資料不是自然產生,而是人為干擾時。因為假如有人謊報數字,則傾向要嘛全部數字平均報、要嘛偏好0或5,總之都會遠離Benford’s Law。Benford’s Law用在選舉上已有數篇研究,但爭議也不小。 包括Carter’s Center(2005)等質疑這測驗方式會讓一些美國乾淨選舉也被質疑,但Mebane(2006;2011)等人則尊稱此測量方式為選舉犯罪學(Election Forensics),可見這篇文章。
把Benford’s Law應用在2012的總統選舉資料時,會碰到的一個大文題,在於我國切選區時,各票匭的總票數會被設計成大致相同以利開票作業,因此不是自然累積產生。為了解決此一問題,Mebane建議在檢驗選舉資料時要驗的是second digit而非first digit,而且不應從最小的票匭驗,而是要數個票匭相加的村里為單位驗。此方法對台灣來說也應適用,因為台灣各票匭數量有設計過,但村里許多是因為自然狀態而產生的。為了驗證,可以先把各村里選舉人數用Benford’s Law檢驗,再來檢驗各黨得票數。我使用的是R裡的BenfordTests package。
各村里選舉人數檢定(Benford’s Chi-squared test):2012年 chisq = 6.7075, p-value = 0.5685 (2digit: p=0.3184)2008年 chisq = 9.1862, p-value = 0.3268 (2digit: p=0.8485),都不顯著,所以各村里選舉人數是符合Benford’s Law的,也就是自然數字。那麼,各總統候選人得票數呢?
- 2012年KMT chisq = 42.7156, p-value = 0.0000009937 (2digit: p=0.001379)
- 2012年DPP chisq = 43.6243, p-value = 0.0000006699 (2digit: p=0.01097)
很顯然地,2012年的兩大黨總統候選人得票都不符合Benford’s Law,這代表兩大黨的得票數字分佈都不太自然,但假如也看看2008年的分佈:
- 2008年KMT chisq = 21.7683, p-value = 0.005364 (2digit: p=0.1634)
- 2008年DPP chisq = 52.8002, p-value = 0.000000001179 (2digit: p=0.002358)
相較之下,2008年的兩大黨得票同樣偏離Benford’s Law,難道這也意謂著2008年的選舉有問題嗎?這又回到Benford’s Law提出的本身,因為這個統計方法目前爭議仍多,而我國村里在切割重畫時各縣市又各自有不同的上限、執行狀況也不同,而就算不是做票,這數字可能也因為計票員的人類心理偏好0跟5的關係而導致不正常。因此這個統計方法一直被視為只是快篩,而不能當作決定性的證據。
小結
做票的方式百百種,筆者曾辦過選舉、也曾梳理過台灣選舉史,在票箱裡偷藏票、拿白票出來換票、計票時亂喊、手偷沾印點票時毀票…做票方式百百種,但都需要現場抓到。本文所討論的三種方法,都是在選舉過後,以事後的方式來分析數字可能不正常之處,惟目前這些方法都還在學界討論,並不能當決定性的證據,畢竟直接以此數字來決定選舉有效與否,是需要特別慎重的。
而本文的三種方法中,只看開票圖的話本文已證明就算好好開也會開出黃金交叉,而從分佈圖Heatmap看不出異常。雖然Benford’s Law顯示開票數字顯著的不像自然界的分配,可是這種統計方法在學界仍在持續發展中,而且這數字異常也並不代表對誰特別有利,因此難以當作做票的證據。在無罪推定的原則下,我們很難說2012年有沒有人真的做票的。
擔心選舉做票、追求選舉純淨,這是哈佛教授Pippa Norris 率領的跨國團隊在近年來的重大研究題目。但目前最有效的方式,還是透過國內外的觀察團直接到各票點據監票、去檢查票箱,如同台灣之前的監票者聯盟。下次選舉又來了,擔心做票嗎?還是湊個一萬人去一萬個投票所吧!事後統計分析還是有其侷限在的。