
◎ 陳方隅/美國密西根州大政治學博士候選人、顏維婷/美國俄亥俄州大政治學博士候選人
近幾年世界各地一直都有大規模社會運動出現,而且特色都是由年輕人所發起,並迅速引起社會各階層的共鳴。例如2008年韓國抗議與美國簽訂自由貿易協定(free trade agreement, FTA),號召了超過一百萬人上街頭,後來該貿易協定退回重談。2010年英國人抗議高等教育學費自由化、漲不停,年輕人上街砸物抗議。2011年阿拉伯之春席捲中東地區,抗議誇張的失業率和長期威權統治,該年也出現各種「佔領」運動,包括佔領華爾街,控訴1%的有錢人掌握絕大多數社會財富。2014年委內瑞拉、土耳其等地都出現大規模抗議貧富不均、失業率高漲等現象的社會運動,與我們鄰近的馬來西亞也在好幾年前開始出現與威權政黨的長期抗戰—訴求乾淨與公平選舉的Bersih淨選運動(馬來語乾淨之意)。
2014年三月份在台灣,我們也經歷了一場非常大型的抗爭:太陽花運動。許多人說:上街抗議的都是「沒競爭力的年輕人」,台灣一定要簽自貿協定才能夠促進競爭力。政府及學者們拚命告訴大家服貿利大於弊(GDP會增加)、經濟與政治無關,但最後宣傳的效果似乎不是很好,人們還是對服貿有巨大的疑問。
(參考閱讀:〈為什麼「利大於弊」無法說服人民:關於自由貿易,人們所想的是…〉,這篇文章整理了影響人們支持貿易協定的各種因素)
其實,到底誰參加社會運動、為了什麼而參加,這些都是可以被檢驗的實證問題。 值得研究的問題有很多,本文主要是想回答幾個問題:是「沒競爭力」的年輕人在反貿易嗎?對於「與中國簽貿易協定」這件事,人們真的能像政府說的那樣子,視為一般的自貿協定嗎?

來源:C.C. by kent Chuang
實驗室裡的太陽花
社會科學也是可以做實驗的!對於以上的研究問題,筆者設計了一個「問卷實驗」(survey experiment),並委託政治大學選舉研究中心執行。所謂實驗方法,最重要的就是「隨機分組」,並讓不同組別的受試者接受不同的刺激(treatment),然後再比較不同組別所展現出來的個人態度差異。在這份問卷中,我們有兩種刺激(第一種有3個類別;第二種有2個類別),我們用隨機的方式分派3×2一共六種不同的問卷給受試者。
每一位受試者皆會收到一段關於自由貿易的政策說明,除了兩處實驗刺激外,其他內文皆同。第一種刺激方式是「貿易對象」,受訪者會看到以下三種其中之一:現在台灣政府正在評估和「中國/日本/馬來西亞」簽訂貿易協定。在一段中規中矩的描述後(例如:提升2-5% 的貿易出口量、經濟成長率(GDP)增加3-4%…等),受試者會看到第二個刺激。第二個刺激是個人獲利程度,受試者會接收到這個訊息:個人薪資在這個政策下可能「增加/減少」3%。
實驗法的特點就在於每位受訪者僅會看到一種組合,例如,如果你看到與「中國」簽貿易協定與「增加3%薪水」的組合,你就不會看到跟「日本」與「增加3%薪水」的組合。透過隨機分派,組別間可形成類似做實驗般的「實驗組」與「對照組」去進行比較。在這份實驗中,我們一共收到831個樣本,平均分散在6個組別中。
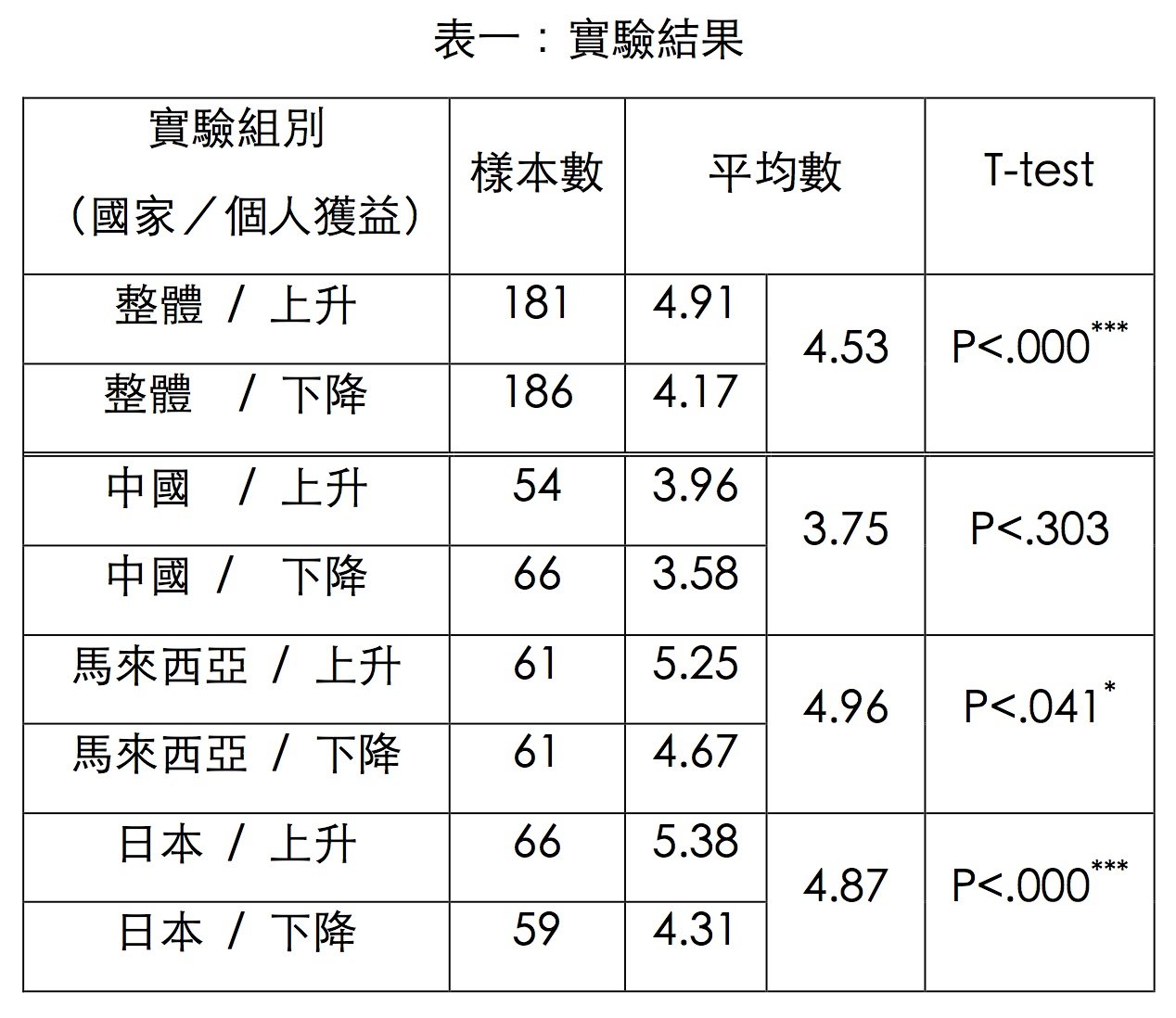
在表一和圖一,我們分別用不同方式呈現我們得到的實驗結果。表一提供實驗的基本結果,包含各實驗組別的有效樣本數、平均數以及統計T檢驗(註:T-test是在測量兩組平均數之間有沒有顯著差異,P值小於0.05並打上*號代表兩個平均數有顯著差異。關於樣本方面,我們刪掉了沒有成功接收刺激的受試者)。
圖一提供圖像化的實驗結果。每個紅框框代表一個國家(第一組刺激),由左而右依序是中國、馬來西亞以及日本。在每一個框框裡,則是第二組刺激,左邊表示個人薪資「增加」3%、右邊則是「減少」3%。Y軸是受試者對於這項貿易政策的評估和支持度,選項由1到7分,1表示非常不支持,7表示非常支持;由於4分是中間值,因此當平均數高於4分時表示受試者偏向支持自貿協議。每條線的紅點代表平均數,線的上下界是統計上的信賴區間(若對統計不熟的讀者可以大致上解讀成受試者給分的最高和最低範圍)。

圖一:實驗結果
中國的特殊之處
在這個實驗裡,我們得到幾項非常有趣的結果。首先,在控制了個人的獲益程度後(也就是比較表一的三組國家平均支持度)會發現,貿易國家對形塑人民貿易支持度是有顯著影響力的!當貿易國是中國時,受試者對貿易的支持度明顯偏低。但若貿易國是馬來西亞或日本時,受試者對自貿的支持度並沒有相差太多,而且支持度都偏高(受試者對與這兩國貿易的支持分數都接近5分)。更有趣的是,在貿易對象是中國的狀況下,即使受試者接收到訊息說這個貿易協定會增加收入3%,受試者對該貿易協議的支持度雖然從平均3.58上升到3.96,可是在統計上卻沒有顯著差異。
換句話說,從實驗結果看來,台灣人大致上是支持自由貿易的,但是卻不認為與中國貿易和與其他國家貿易可以完全一概而論。不只是在支持度平均分數上面,與中國簽貿易協定獲得的支持度顯著偏低,就算個人在其中獲益,也沒辦法顯著提升支持度。顯然中國與其他國家相比有其特殊之處,以致於人們在面對中國時,會因考量「經濟以外的因素」而格外小心。
如果貿易對手國是重要的,那麼這項實驗結果也說明了為什麼政府和學者們「利大於弊」的說帖不僅無法說服人心,反而離民意越來越遠。因為對台灣人來說,與中國發展自貿的疑慮不全然是經濟考量,同時還有政治考量。而且從台灣人普遍不反自貿的實驗結果看來(在同一份問卷裡我們也問了民眾對開放貿易的一般性看法,有高達84%的受訪者認為增加出口對台灣有利),對中國的疑慮是政治因素大於經濟因素。因此,政府該做的,應該是成立更完善的兩岸監督機制,並確保更開放的政治過程,讓全民可以有妥善監督及參與的管道,如此才能化解社會的疑慮,而非一再請人民相信政府、或恐嚇人民不開放台灣就會鎖國。這樣的說服方式只會帶來反效果。
競爭力不是影響貿易支持度的唯一標準
政府的說帖與輿論中,同樣存在很多認為「支持太陽花的年輕人根本是害怕競爭所以不敢走出去」的看法。換句話說,許多人認為「沒競爭力」的人才會反對貿易協定。發表這類高論者(通常也是認為自己很有競爭力的人),認為大家該做的是回家念英文、多培養自己的競爭力,而不是怕競爭。然而,事實真是如此嗎?競爭力的高低真的是影響一個人支持自貿與否的唯一因素嗎?
筆者的實驗直接提供證據來檢驗這樣的說法,我們得出的結論是:有競爭力的人不一定會支持自貿,沒競爭力的人也不都全然反對自貿。從表一的結果來看,有競爭力的人(能在此貿易政策下獲利的人,高收入與高學歷的族群)一般來說,的確是會比較支持自貿協議。不過,在同一個結果中,我們也發現競爭力高低是否會影響對自貿的支持度其實也與貿易對手國有關。當貿易國為日本時,個人獲益與否影響貿易支持度的程度最高(圖一最右邊的框框裡,左邊和右邊兩條線間的差距最大)。反觀,當貿易國為中國時,我們發現個人競爭力高低並無法解釋對中國自貿的支持度(圖一最左邊的框框裡,左邊和右邊兩條線是重疊的)。顯然,面對一般國家時,個人競爭力高低的確會影響一個人對自貿的支持度;但當面對中國時,政治因素的考量會壓過個人競爭力的因素,去影響一個人對自貿的支持度。
所以,請不要再說支持太陽花的人都是來亂的了。從筆者的實驗結果看來,台灣人對於自由貿易的偏好是非常理性的。個人競爭力並非唯一影響自貿偏好的因素,人們同時也在意非經濟因素,也就是在意一項貿易協定是否對整體國家不利(這在政治經濟學的研究當中,叫做sociotropic view)。
而人們考量貿易協定對國家和社會是否有利,會去考量經濟因素(能夠拚經濟嗎?會帶來貧富不均嗎?)和非經濟因素(有沒有政治動機?)。當人們對於一項貿易協定背後的政治動機有所疑慮時,很可能將個人的利益擺在次要的位置,而去考量這項協議對國家整體的影響。我們的實驗結果也呼應巷子口社會學之前<誰來「學運」?太陽花學運靜坐參與者的基本人口圖象>這篇文章的結論:「從參與者來自菁英大學偏高的參與程度,太陽花是一場帶點菁英性的學生運動」。我們認為,那些高學歷、最有可能在自貿中獲利的那些「競爭力高」的人,也同樣會走上街頭,去抗議對整體社會有影響,或是對國家安全疑慮的自貿協定。
年輕人反中、反自貿?
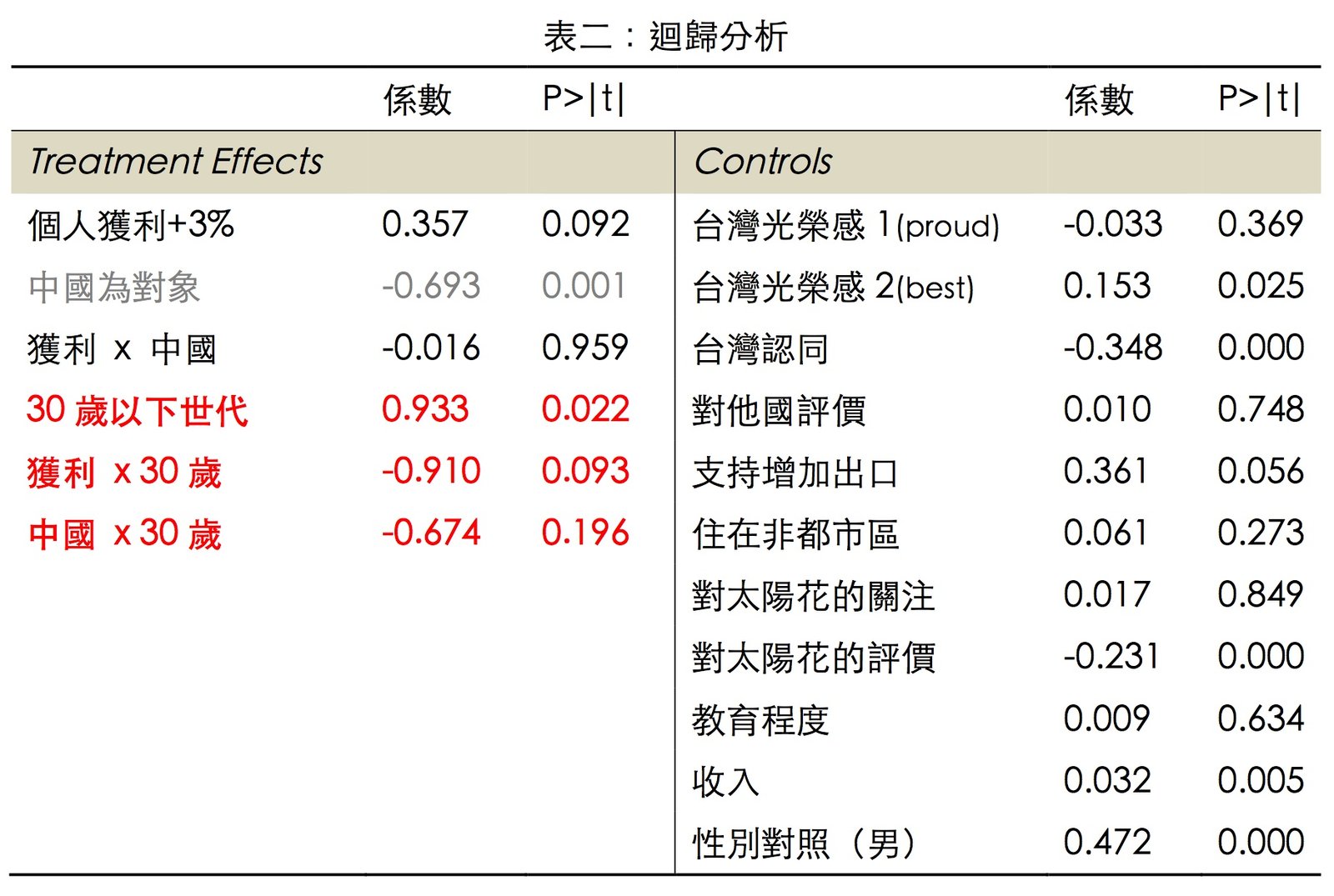
最後,筆者們想檢驗30歲以下的年輕人和上個世代相比,真的有特別反中或反自貿協定嗎?我們以對自貿的支持度為依變項、放入各種不同的實驗組合與控制變數去跑迴歸模型,結果如下。
首先,和前面已得出的結果一致,當貿易夥伴是中國時會降低人們對貿易的支持度(綠色項目)。再來,30歲以下的年輕人不僅沒有比較反自貿;相反的,和上一代相比,年輕人普遍來說反而更支持自由貿易。此外,在控制貿易國為中國以後,30歲以下的年輕人和其他族群相比也並沒有特別的反對貿易。(以上請見三個紅色的項目。P<0.05為顯著,係數的正負號表示該變數與依變數之間是正相關或負相關。例:30歲世代比其他世代對自貿支持度,平均而言顯著高了0.933分。)簡而言之,年輕人並非一個特別的族群,沒有特別反中或反自貿。
小結
透過問卷實驗法,這篇文章提供一些實證資料來回答:究竟台灣民眾在形塑貿易政策偏好時,會考量哪些因素?我們得到的研究結果如下:其一,面對自貿協議,人們並非只考慮個人薪水的增減與競爭力的高低,國家整體是否能獲益也是重要考量。其二,中國因素的確存在,即使在被告知「個人薪資會上升」的情況下,人們仍然對與中國貿易特別謹慎。和其他兩組貿易對照組相比,我們認為,這是由於對國家安全以及相關政治因素的疑慮,而這其實也是理性考量的結果。其三,年輕人並沒有特別的反中與反自貿。
換句話說,太陽花是一場全民的運動,並非年輕的、競爭力低的人們因為怕開放經濟競爭而發起的。
作者您好,
抱歉我才疏學淺,
針對文章中有一些不是很瞭解的地方,
還希望您能再說明:
1. 雖然6組有隨機分派,但各組在統計上確實是相似的嗎(至少如年齡、性別、教育程度、收入等)?另針對接受實驗者的selection bias怎麼處理?
2. 從表一跟圖一都沒有辦法看出「有/無競爭力的人」的情況,或是本文直接將「支持自貿的人」比成就是比較有競爭力的人嗎?
3. 就我所知,太陽花學運是「反黑箱服貿」,但文中好像變成支持太陽花學運就是「反自貿」。
謝謝您。
謝謝提出問題。
1各組背景–>是的,隨機分派的用意就是要讓這些條件都趨於一致。
1接受實驗者的selection bias–>您的意思是說,主動說要填答跟不想回答的人會有selection bias嗎?這的確是有可能,不過我們就是盡量從題目設計上面讓大家覺得這是一個中性的問卷,而不是一個實驗。是在他們作答完之後再做一個簡介。而且,因為大家的背景都是呈現隨機分布的,再加上,從對貿易支持度這個變數來看,其實整體來說大家都是很支持貿易的(平均分數),跟其他地方做的survey差不多,所以我們是覺得bias應該不大。
2我們是把個人獲利的人等同於有競爭力的人(因為要有競爭力才會獲利)
3太陽花有許許多多不同的面向(每個人所關注的面向都有可能不一樣)。
我們並不認為「支持太陽花學運就是『反自貿』」
我們是特別想要反駁一種說法,即:政府及許多支持者希望大家支持服貿,並且一直說跟中國的貿易協定就是單純的自貿協定。但是明顯不是,因為人們還會考慮許多因素。
感謝您的回覆,但對於研究我還有些問題:
1. 我知道隨機分派「理論上」可以使受試者各項條件趨於一致,但如果能將六組的基線資料一併比較(baseline comparison),至少如民眾對開放貿易的看法此變項,更可以增加本研究的說服力,這也是我前次第一個問題的前半部所要問的。
2. 從您的回應來看,我理解為「分到獲利組的人」就是「假定有競爭力的人」。但獲利者為有競爭力(獲利→競爭力),跟有競爭力者獲利(競爭力→獲利),因果關係是不相同的。即便研究中的受試者獲利,難道就會變成跟本研究界定「有競爭力者」的思維模式一樣嗎?我認為頂多能說,能從中獲利者也不見得支持該項自貿協議,再推論到競爭力高低就可能會有問題。
3. 接續上題,我覺得「獲利或損失多少」可能也會是影響的重要因素。研究中定為3%,也許設定不同獲利或損失水準,會呈現很不一樣的結果,也許未來您也可以再試試。
4. 再來,就是如何從本實驗推論到太陽花學運?畢竟參與運動者與實驗對象顯然不全然是同批人,您也說解讀太陽花有許多不同角度,所以如何以本研究推論到整個太陽花學運呢?
5. 另外,既然已經可以做到隨機分派,為什麼不盡量讓各組人數一致?雖然各組差距不是很大,但是否在研究設計上有限制才會如此?文中有說「關於樣本方面,我們刪掉了沒有成功接收刺激的受試者」,但我不是很清楚是什麼意思。
不好意思,問題有點多,謝謝了。
1—>這個建議真不錯,我們之後若繼續投稿的話,會把它做成附錄。
2—>其實我們一開始是把高學歷、高收入的人定義成有競爭力的人(並把這兩個變項放在模型中),而這也是政治經濟學當中最常見的定義。
不過我們在本文中的確有一點把前兩類的人跟有獲利的人混在一起寫了,寫得不夠精確。
3—>這的確就是我們未來想要做的題目!!!!!!非常感謝提出來,我們現在更有動力去申請funding,哈!
4—>您的批評都還滿到位的。的確,支持太陽花跟支持服貿是兩件事情,不一定完全重疊,這又是另一個寫得不夠精確的地方。
我們原始的實驗設計是在測服貿(或說,與中國自由貿易)的,應該說我們這篇文章是原始實驗設計的implication。
5—>現在各組人數還算是一致啊XD 因為是隨機分派的,所以自然會讓各組的人數差不多。
會差比較多的原因是,我們有一個後測,問說:請問你剛看到的訊息說你的收入會增加還是減少多少?以及,請問你剛剛是回答我們要跟哪一國貿易?
問這兩個問題來確定說,受試者的確知道我們在問什麼。如果答錯的,我們就視為失敗的樣本,不納入分析。
很喜歡你研究的動機及方法
以下有幾點小小建議
1. 表一的實驗結果 用T-test 是最簡單的做法 可以試著考慮用一些無母數的分析方法 Rank sum test 我猜結果應該會一致 但 因為T-test 還是有個常態分配的假設 而1-7的問卷 要說服從常態分配的假設 比較難一點 當然樣本數還算滿大的 應該不會有太大問題 同樣的問題 在第二個迴歸分析也會出現 我在最後一點說明
2. 表一可以利用ANOVA 來分析 會比個別用T-test來分析更恰當一點 例如 還有一個東西可以分析 卻是T-test 做不到的 三個國家的差異 我想這也會是一個有趣的 因為大概可以想像 只要是中國分數就低 日本 馬來西亞分數就高 例外ANOVA 有可以回答上一個人的問題 有個baseline 來做比較
3. 而你文中 中國的特殊之處 就可以用 ANOVA 的 Two-way interaction來解釋
4. 圖一可能可以用Box-plot 來代替 這樣就不用說一個 統計信賴區間 因為 這個東西可能被問得更多 是95% confidence interval? or 90%
5. 如果p-value < 0.0001 通常不會用0.0000來表示 因為p-value 不會是0 而會用<.0001
6. 支持度(1-7)當依變數 跑迴歸 會滿危險的 當然本研究指看 迴歸模型的係數 沒有去預測 但如果用此模型預測 可能會得到完全不合理的答案 例如 對太陽花評價很高的人 對於服貿的支持度是-1 但 -1代表什麼 就沒有定義了 可能可以用一些 order statistics 的模型 會更加合適
剛好有朋友介紹這篇 又滿喜歡這主題 就認真看了一下 呵呵 謝謝!
謝謝Po-Hsu Chen提出的建議!
1~3的建議我們之後會再試試!
4和5—>之後會做修正。
我們這篇其實是一個研究的初稿,所以呈現出來的並沒有去精緻化。謝謝指出問題
6—>沒錯,把依變數視為類別變數去跑模型,會更直觀一點
不過我們的確也沒有要去預測什麼,只是想比較不同組別對服貿的支持度。
非常感謝!